 ���ں�
���ں�CPUʧҵǰ�ף�Ӣΰ�﹫���Կ�ֱ��SSD����
2022-03-18 18:23:26
- +1 ������
���켫��DIYӲ��Ƶ������ͳ�����ݶ�ȡ������CPUִ�������ַת��������ҳ��İ������ݼ����Լ���������ڴ������Ĵ������ݹ�����������Ϊ���Ժ��IJ���֮һ���Կ�����ֱ�Ӵ�SSD�ж�ȡ���ݡ��������˹����ܺ��Ƽ����������GPUֱ�Ӷ�ȡSSDӲ�������ݣ������Ч�ķ�ʽ��

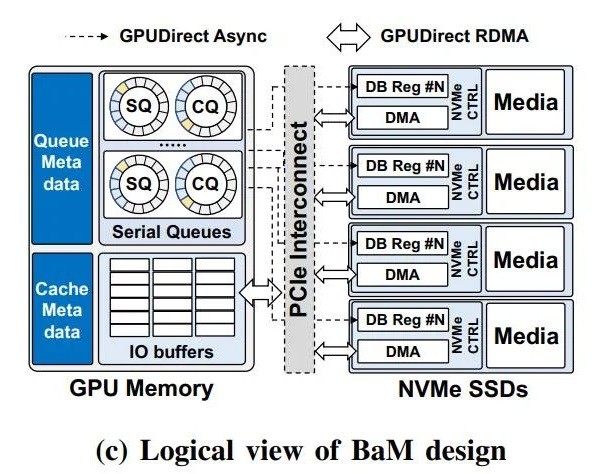
Ϊ����GPUӦ�ó����ܹ�ֱ�Ӷ�ȡ���ݣ�Ӣΰ������IBM��ͨ���뼸����ѧ�ĺ�������һ���¼ܹ���Ϊ�������ݴ洢�ṩ���١�ϸ���ȷ��ʡ���Ҳ������ν�ġ���������ڴ桱(Big Accelerator Memory�����BaM)��ͨ����һ�������ܹ�����GPU�Դ���������Ч�����洢���ʴ�����ͬʱΪGPU�߳��ṩ������㣬�Ա����ɰ��衢ϸ���ȵط�����չ�ڴ����еĺ������ݽṹ��
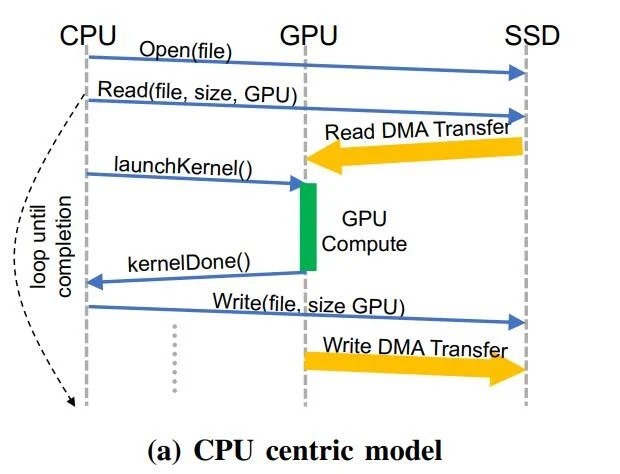
������ͨ�û���˵��BaMӵ���������ƣ���һ�ǻ�������������GPU���棬���ݴ洢���Կ������Ϣ������䣬������GPU�����ϵ��߳�����������ͨ��ʹ��RDMA��PCI Express�ӿ��Լ��Զ����Linux�ں���������BaM����GPUֱ�Ӵ�ͨSSD���ݶ�д��
�ڶ����Ǵ�ͨNVMe SSD������ͨ������BaMֻ�����ض����ݲ������������Ļ�������ʱ������GPU�߳����òο�ִ���������������������ͼ�δ����������з��ع������ص��㷨���ܹ�ͨ������ض����ݵķ��������Ż����Ӷ�ʵ�������Ҫ��Ϣ�ĸ�Ч���ʡ�
����CPUΪ���ĵIJ��Ե����У�����ΪCPU��GPU֮������ݴ����Լ�I/O�����ķŴ����۾���ϸ���ȵ�������ط���ģʽ���о���Ա��BaMģ�͵�GPU�ڴ��У��ṩ���ڸ߲���NVMe���ύ/��ɶ��е��û����⣬ʹδ�����������ж�ʧ��GPU�̣߳��ܹ��Ը��������ķ�ʽ����Ч���ʴ洢��
����Ҫ���ǣ�BaM������ÿ�δ洢����ʱ�������������ͣ���֧�ָ߶Ȳ������̡߳��ڻ���BaM���+��GPU+NVMe SSD��Linuxԭ�Ͳ���ƽ̨�����ʵ������У�BaM�����൱ϲ�˵ijɼ���
��Ϊ�������CPUͳ��һ������Ľ��������BaM���о��������洢���ʿ�ͬʱ����������ͬ�����ƣ�������������I/O����Ч�ʣ���Ӧ�ó�������ܻ�ô��������NVIDIA��ϯ��ѧ��Bill Dallyָ�����������������棬BaM�������������ڴ��ַת��������������TLBδ���е����л��¼���
�༭����������Resizable BAR��SAM�����ķ�չ��Ӧ�ã�GPU��CPU֮��Ĵ���ƿ���õ�����Ļ��⣬������ڴ�CPU��ȡ���ݣ���GPUֱ�Ӵ�SSD�л�����ݵ�Ӧ��Ч�ʻ���ߡ���Ȼ�µ�BaMĿǰ��δ��ȷ���������������Ӧ�ã������Ų��ú�Ҳ������ز�Ʒ������











ϧ
������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼


























