 ���ں�
���ں�28nm+ȫ�¼ܹ� AMD��һ��GPU���ǰհ
2011-08-02 17:09:20
- +1 ������
���켫��DIYӲ��Ƶ�������Ǽ����һ��AMD��һ��GPU�Ľṹ��������������������һ��ͨ�õ�������������������������GPU���������֧�֣����GPU����Ϊһ���µ�Э��������
�����������Ķ��߿������Ѿ������˲�ֻ3D��Ϸ����GPU��Ƶ����Щ��������3D��Ӧ�ó���ʹ�û�GPU���ٵ���һ���涼�����ӡ�����������������FP�����������ض��������ж��о�ı����Դ���������ڸ����ܺ�̨ʽ������������ң�Linux��Windows���������ڶ�֧������ˡ������������Ƴ�����C++AMP��������GPU��������ںܶ�����ﹲͨ��
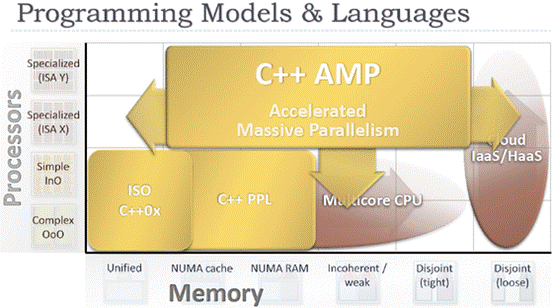
Ȼ�������ܽ�GPU�Ľ�������ת��Ϊһ�ָ������ٵ���ѧЭ���������������𣬾���������20����90�����80x86��������80x87 FPЭ������(������Macs��Ħ������680x0 CPUҲһ��)��������Intel����Ψһ�������ַ�ʽ�ģ���Ȼ���ڻ�Ϊʱ���硣AMD����һ��GPU���죬һ����ǰ��Fusion���Ի����Ͼ�չʾ�ˣ����������֮ǰ��Radeon HD7000ϵ�г���ʵ��һ��28nm�Ƴ̡�
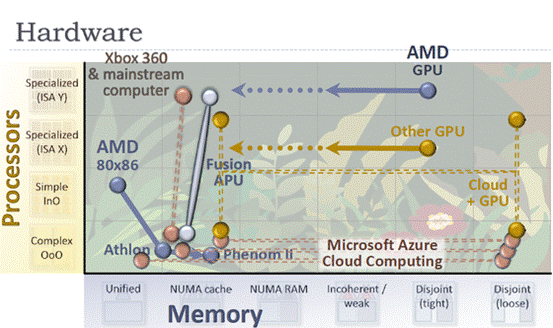
����������ͼ���Ͽ�������������������GPU���ᳯCPU�����ٽ�һ����ʹ���ͨ��Ҳ�����״�ɷ����������ܱ����㷺��Ӧ�ó�����ʡ����ԣ���ͨ��Э�����������տ��ܱ�������塣

�ڹ۲�����ṹ����֮ǰAMD��Nvidia��Ʒ�Ƚ�֮���ҵó�������һ��AMD GPU��ĿǰGeForce���ϵ�Nvidia Fermi����һ����ͼ�ι��ܵ����������������������������ģ�����������̸�۵���һ��оƬ�ڵ�����Cray�������������X86���ݵ�64λ��ַ���ڴ���������������ϵͳ����X86�ܹ���������������ڴ棬���������ij�ַ�ʽͨ��Hyper Transport����QuickPath(��������������Ӣ�ض��ķ�����������)������CPU���������Լ����ڴ���Ϊһ��������Ϊһ����Ϻ������������Խӽ�CPU���ٶȴ���������Ҫ�ڴ棬����û��PCLeƿ����
��ע���ǵģ����˻Ὠ��PCLe v3����ʹ����������Э������CPU��GPU�����Ľ��п��ٵ��ڲ�����������������һ����һ���߳̽�������ڴ�������û��ʲô�ܴ����HTX����QPI�ij����٣�����ʱ������һ�µĻ������ӡ�
������Ѿ������Ͽ�����ʽ�����汾�Ĺ�����һ��AMD GPU���죬Ȼ��������������һ��һЩӦ�ñ������ĵط��Լ�AMD����ǿ���ĵط���
������������һ������Э�������̶����ܵ�ͼ��Ӳ����Χ������������
��ÿ�����㵥Ԫ����һ��4��MIMD�˿�����64-op FMAD���������������40·SMT����
��ÿ�����㵥Ԫ��������16KB��L1���ٻ����64KB L2������Ա����е�CU��CPU����
��������X86�ĵ�ַ��ָ������ҳ����ϣ��ڴ��L2���ٻ�����CPU��GPU�ﶼ��һ�µ�
����ͼ�����У���Щ������λ����Ϊһ��ͳһ����ɫ�����У����ƺͰ���3D�����Ӳ������Ƕ�����Σ�������ɨ��ת��������Ƶ����Ӳ����������һ��������������ѧ���棬�����������Ѱ��һ��Э��������Ψһȱ�ٵ���X86ָ���չ���ڻ�������ֱ�Ӵ�������ϣ���ⲻ�ᷢ������X86��ij������˵�Ѿ������ˣ���Ϊ��ʷ����ԭʼ��ָ����ܣ���ѹ���Ե��������ŵ�սʤ��һ�ж��֡�
���ҿ��������оƬ����ѧ����������һ����1GHzĬ��ʸ�����㵥ԪƵ�ʣ�������64��64λFMAD�����ں�64λ�˼ӡ���ÿ�����ڵ�ҵ����ҵ��ʸ����Ϊ64���ֿ�(���״�ʵʩʱ��������Ȼ��64x32λֵ���������������������)���ڼ���FLOP�ֵ��ʱ��˳����һ�䣬ÿ��FMAD��Ϊ����FP ops���������ԣ���1GHz��ÿ�����㵥Ԫ�����Ͽ����ṩ128 GFLOPs��˫����(���ߵ����ȣ����ֻ��64x32λֵ�ڸ�����)��������Ϊ��������е�HD6970��˫��������������ֻ��Ҫ7�������ļ��㵥λ���ٴμ��裬�µĵ�λ�ǻ���64λ֮�ϵġ�16����λ��оƬ������2��TFLOPS������������������
��Ȼ��AMDδ��������߸߶�chippery���ڴ������������Щ��λ�������Ҹҿ϶�����384λ����������512λGDDR5�ͳ��������ڴ���ڴ���ϵͳ����������֡���λ��ֻ�����˴������������������ܵ�������4GB����RAM��2 Gbit GDDR5оƬ�����ɣ�����8GB��˫���ɣ��ڱ��صĸ߿����������������ܶ�ļ�����������CPUҲ�ܽ����ӳ��ڴ桪��ʹCPUͨ�������ڴ������ֱ�Ӵ���GPU���ڴ档
����������Ӱ�쵽Nvidia��Intel�IJ�Ʒ�أ�Intel�ġ�Knights����ͥ��ԭ��Ԥ�ƴ����������һ��������22nm�Ƴ̵IJ�Ʒ�������൱��ʱ������תЭ����������ֻ����ΪCPU�Աߵ���һ��������������X86��ǰ�ˡ����ͨ��QPI���ӵ���Xeon E5 Sandy Bridge/Ivy Bridge�����ǣ����������Լ����ڴ�ϵͳ�൱��Ľ������е��ڴ档Ȼ���������Larrabeeͼ������ʧ��֮��Intel����Ҳ�������ǵġ����������ص������Щ���ʸ��оƬ������ͼ��HPC����������������еĻ�����������ģʽ������Ҳ�൱�����µ�AMD GPU���㷢չ�����г�����ͼ��
����Nvidia�����ǿ��Ժ����ĸ���AMD�ķ��������Ͼ���Fermi��һ��ǰ�Ѿ�����ͨ��Ŀ���GPGPU������ǰ���ˡ����ǣ�����GPU��Intel��AMD��CPU�ӱ�������������᷽�棬���ܶ������ס�Nvidia������������Intel��QPI����֤��������HyperTransport���ɸ���ѡ����Ҫ���PCIe GPU���������κ�CPU�����ܵ����ӣ����Ǵ���HyperTransport���ӵ�GPU�����Ƶ�AMD GPU����һ���൱��С�ĸ߶�AMD CPU�г���
�ܶ���֮�����AMDʹ������µ�GPU�ṹ��28nm��Radeon HD7000ϵ����⽫��Ϊ����ǰGPU����ֿɱ��������֮������GPU���¡����ǵ�Ȼϣ���ⲻ��Ӱ���ͼ�����������ܺ��ȶ��ԣ�����һ������ĸԽλ���⽫����һ���dz���Ȥ����ϵͳ������Ӧ�ó����ṹ���ǵģ�һ�λ���������˺ͺ����ٸ���խ�ں���Ӧ�ó����������������һ����ս��������������֤�����ܳ�������
ԭ�����ӣ�//vr-zone.com/articles/next-generation-gpus-amd-s-cray-on-a-chip-/13163.html










����
������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼


























